
西南交通大学信息科学与技术学院,四川 成都 611756
Overview: In the fields of engineering and computational science, finite element analysis is a commonly used numerical simulation tool. Its accuracy and efficiency directly affect the reliability and computational cost of engineering design. However, traditional adaptive mesh refinement technology faces certain challenges in the pursuit of high-precision and high-efficiency collaborative optimization. Especially when dealing with engineering problems with singular fields or complex boundary conditions, traditional iterative methods often show the problems such as uneven gradient error distribution and slow convergence. These limitations not only affect the accuracy of the calculation results, but also limit the application of finite element analysis in complex problems. To address the above problems, this study proposes an adaptive mesh partitioning framework based on the attention fusion mechanism, namely GATv2-Transformer fusion network (GTF-Net). This method transforms the mesh partitioning problem into a node classification problem. Each mesh node is regarded as a node in the graph, and the edges between nodes represent the relationship between units. The relationship between mesh units is modeled using graph neural networks, thereby achieving adaptive adjustment of mesh partitioning. Graph neural networks automatically adjust the mesh structure by learning these relationships. The network innovatively combines the graph attention mechanism with the Transformer architecture, and realizes the dynamic coupling of local geometric features and global physical fields through multi-head cross attention modules, effectively improving the representation ability of complex environments. The analytical solution of multiple equations is introduced into the network training, and a multi-task learning objective is constructed to ensure the generalization performance of the model under different physical field characteristics. The typical optical waveguide transmission problem example and the solution results of the first-kind Bessel function show that compared with the traditional skFem method, GTF-Net has improved the calculation speed while reducing the standard deviation of the gradient error by more than 20% (the Bessel function case is reduced by 23.8%, and the optical waveguide case is reduced by 85.9%). The experimental results show that the network significantly improves the matching degree between the grid density distribution and the physical field changes through nonlinear mapping of the feature space, and the method has a certain generalization ability and can adapt to different types of problems and application scenarios. This method provides a new deep learning solution for adaptive finite element analysis in engineering calculations, and also opens up a new technical path for the development of data-driven intelligent finite element analysis.
自适应网格细化 GATv2-Transformer融合网络 有限元分析 深度学习 adaptive mesh refinement GATv2-Transformer fusion network finite element analysis deep learning 
1 上海工程技术大学机械与汽车工程学院机器人研究所,上海 201620
2 上海大型构件智能制造机器人技术协同创新中心,上海 201620
Overview: A wearable fiber Bragg grating neck pulse monitoring device has been designed to address the shortcomings of current neck pulse monitoring devices, including inconvenience in wearing and complex signal processing. This device is not affected by temperature, offers portability and comfort, enhances monitoring sensitivity, and can track the neck pulse frequency of the human body under different states. The device has been optimized for comfort, ensuring that users experience greater comfort during monitoring. Calibration experiments have shown that its pressure sensitivity is 40 pm/N, with a fitting goodness of 0.9985. The error between the theoretical sensitivity and the calibration experimental sensitivity is only 2.663%, which is relatively low. A temperature comparison experiment was conducted, and the maximum error was found to be 1.750%, demonstrating that the performance of the device is minimally affected within a certain temperature range. The device underwent 72 h aging experiments under temperature and force conditions, and the maximum wavelength variation at adjacent time points was 1.12 pm and 1.11 pm, indicating minimal change and proving that its performance is not significantly affected under these conditions. The device was subjected to a 1 h signal attenuation experiment, where the maximum attenuation rate was less than 0.1%, indicating that the signal attenuation over the hour was negligible. volunteer 1 used the device to monitor the neck pulse for 10 s at 15:00, 17:00, 19:00, 21:00, and 23:00 on the same day. The ICC coefficient of the five monitoring data points was 0.99383, indicating high consistency between the five sets of data. The device was used to monitor volunteers 1 and 2 under sitting and lying down in different states (resting, exercise, and vigorous exercise) for 10 s each, and it was observed that while the peaks and valleys of the pulse waves exhibited some differences, their periodicity was almost consistent. The first complete cycle of each state was processed and analyzed by spline interpolation, and the results of comparison with theoretical pulse wavelength changes showed consistent trends. Fourier transform processing was applied to the data, and the frequency error with that of wristbands and pulse oximeters was found to be less than 10%. Pearson correlation coefficient of the periods for different states yielded a correlation greater than 0.9. Finally, random forest was used for predictive analysis, and the evaluation results showed that the prediction was accurate. The analysis above indicates that the neck pulse monitoring device can effectively monitor the neck pulse of the human body.
光纤布拉格光栅 颈部脉搏监测 傅里叶变换 皮尔逊相关系数 随机森林 fiber Bragg grating neck pulse monitoring Fourier transform Pearson correlation coefficient random forest 
宁波大学信息科学与工程学院,浙江 宁波 315211
Overview: Point clouds are widely used in virtual reality, computer vision, robotics and other fields, and distortion assessment in point cloud acquisition and processing is becoming an important research topic. Considering that the three-dimensional (3D) information of point cloud is sensitive to geometric distortion and the two-dimensional (2D) projection of point cloud contains rich texture and semantic information, this paper proposes a no-reference point cloud quality assessment method to effectively combine the 3D and 2D feature information of point cloud and improve the accuracy of quality assessment. The farthest point sampling is firstly implemented on the point cloud, and then the non-overlapping point cloud sub-models centered on the selected points are generated, to cover the whole point cloud model as much as possible. For each point cloud sub-model, an improved 3D multi-scale feature extraction network (MSFNet) is designed to extract the features of voxels and points. MSFNet contains three point-voxel transformer (PVT) modules and generates output features through a multilayer perceptron. Each PVT module has two branches. The voxel branch can extract rich semantic features from spatial voxels; the point-based branch can retain the integrity of the point cloud sub-model position information as much as possible and avoid the loss of position information. For 2D feature extraction, the point cloud is first projected with orthogonal hexahedron projection to obtain the corresponding projection maps. To extract the rich texture and semantic information from the 2D projection maps, a 2D multi-scale feature extraction network (MSTNet) is designed to extract 2D content-aware features. Considering that there may be a large amount of redundant information and certain dependency relationships between different viewpoint projection maps, MSTNet uses spatial global average pooling operation to remove redundant information and spatial global standard deviation pooling operation to preserve the dependency information between different viewpoint projection maps. Finally, considering the process of segmentation and interweaving fusion that occurs when the human visual system processes different modality information, to better fuse the 2D and 3D features of the point cloud, so that the two modality features can enhance each other, a symmetric cross-modality attention module is designed to integrate the 3D and 2D features, and a multi-head attention mechanism is added in the feature fusion process. The experimental results on five public point cloud quality assessment datasets show that the Pearson's linear correlation coefficient (PLCC) of the proposed method reaches 0.9203, 0.9463, 0.9125, 0.9164, and 0.9209, respectively, indicating that the proposed method has advanced performance compared with the existing representative point cloud quality assessment methods.
点云质量评价 三维特征 二维特征 对称跨模态注意模块 point cloud quality assessment 3D feature 2D feature symmetric cross-modal attention module 
北京印刷学院高端印刷装备信号与信息处理北京市重点实验室,北京 102600
Overview: The previous screen content image quality assessment algorithms failed to fully consider the multi-level visual perception characteristics of the human eye. To address this limitation, we propose a multi-task attention mechanism-based no-reference quality assessment algorithm for screen content images (MTA-SCI), which better simulates human visual perception. The MTA-SCI combined the advantages of both global and local features of SCIs, enabling it to capture the overall structure while focusing on visually significant details. This approach significantly enhanced the SCI quality evaluation capability. Specifically, the MTA-SCI employed a self-attention mechanism to extract global features, improving the representation of overall information in SCIs. Subsequently, it utilized an integrated local attention mechanism to extract local features, allowing the algorithm to focus on more salient and attention-grabbing details in the images and suppressing channels containing background texture noise, reducing the impact of background texture noise on image quality assessment. The integrated local attention mechanism consists of the group-wise attention mechanism with spatial shifts and asymmetric convolutional channel attention mechanism. In the MTA-SCI algorithm, they perform different tasks, working together to improve the performance of screen content image quality assessment. Finally, a dual-channel feature mapping module is adopted to predict SCI quality scores. In the first channel, it predicted the quality score of image patches; in the second channel, it predicted the saliency weights of the image patches. The dual-channel feature mapping module effectively quantifies the importance of different image patches within the overall image, making the predictions more aligned with subjective human assessments. Experiments on the SCID dataset demonstrate that the proposed MTA-SCI achieves a Spearman’s rank-order correlation coefficient (SROCC) of 0.9563 and a Pearson linear correlation coefficient (PLCC) of 0.9575. On the SIQAD dataset, it achieves an SROCC of 0.9274 and a PLCC of 0.9171. Overall, the multi-task attention mechanism consists of three components: multi-head self-attention mechanism, group-wise attention mechanism with spatial shifts, and asymmetric convolutional channel attention mechanism. These three attention mechanisms perform different tasks in the proposed MTA-SCI algorithm, working together to improve the performance of screen content image quality assessment. By integrating self-attention for global feature extraction, integrated local attention for detail refinement, and a dual-channel feature mapping module for prediction, MTA-SCI effectively captures the complex perceptual characteristics of the human visual system. The high performance achieved on benchmark datasets validates its accuracy and reliability, making it a promising solution for future applications in screen content image quality.
屏幕内容图像 无参考图像质量评价 vision transformer 多级视觉感知特性 注意力机制 screen content image no-reference image quality assessment vision transformer multi-level visual system of human attention mechanism 
1 嘉兴大学信息科学与工程学院,浙江 嘉兴 314000
2 浙江工业大学计算机科学与技术学院,浙江 杭州 310000
3 宁波大学信息科学与工程学院,浙江 宁波 315000
Experimental results demonstrate that ADAN significantly outperforms state-of-the-art algorithms on multiple public remote sensing datasets in terms of quantitative metrics (e.g., PSNR and SSIM) and visual quality, validating its effectiveness and superiority. The main contributions are as follows: 1) Proposing a novel method, ADAN, tailored for remote sensing image super-resolution tasks; 2) Designing parallel channel and spatial feature extraction modules along with a gated convolution module to comprehensively explore features across channel, spatial, and convolutional dimensions; 3) Introducing a multi-scale feed-forward network (MSFFN) to effectively explore potential scale relationships and enhance global representation capabilities; 4) Experimentally validating the superior performance of ADAN in remote sensing image super-resolution reconstruction. This research provides new insights and technical pathways for remote sensing image super-resolution reconstruction.
双域注意力 Transformer 注意力机制 遥感图像 超分辨率 dual-domain attention transformer attention mechanism remote sensing images super-resolution 
1 天津职业技术师范大学汽车与交通学院,天津 300222
2 智能车路协同与安全技术国家地方联合工程研究中心,天津 300222
Overview: With the exponential growth of processor computing power and the continuous breakthroughs of deep learning algorithms, deep learning-based computer vision has become a key component in the field of object detection. In the field of traffic supervision, the use of a UAV remote sensing platform equipped with advanced sensors and deep learning algorithms achieves intelligent vehicle detection. This approach provides technical support for the construction of a new rapid response and accurate determination system for traffic accidents, laying a solid foundation for its implementation. Traditional object detection algorithms primarily depend on extracting distinctive features from the input data. These methods require stable lighting and minimal interference during data acquisition, limiting their effectiveness in dynamic scenarios where lighting, shadows, and weather changes affect detection accuracy. Therefore, this paper proposes an improved YOLOv8-GAIS object detection algorithm to achieve effective object detection in urban expressways under low-brightness scenes. The FAMFF (four-head adaptive multi-dimensional feature fusion) strategy is specifically designed to enhance the spatial filtering process, effectively managing conflicting information within the data. To further enhance performance, particularly in scenarios involving aerial views, a small object detection head is incorporated into the system. The SEAM (spatially enhanced attention mechanism) is incorporated to improve the network's ability to enhance the feature extraction ability, particularly in low-brightness environments and occluded parts. This enhancement enables the network to better detect parts of objects that might otherwise be missed due to occlusion. Additionally, the InnerSIoU loss function is utilized to give greater weight to the central areas of objects, thereby significantly enhancing the model's performance in detecting occluded objects more accurately. To enhance the generalization ability of the algorithm, this paper also expands the VisDrone2021 dataset by incorporating field collection scenarios. Comparative experiments reveal that the enhanced model achieves several improvements over the baseline. It reduces the parameter count by 1.53 MB, and increases mAP50 by 6.9%, and boosts mAP50-95 by 5.6%. Additionally, the model's calculation wreduced by 7.2 GFLOPs, leading to improved efficiency and faster processing times without compromising detection accuracy. To further assess its effectiveness, field experiments were conducted along Dagu South Road in Jinnan District, Tianjin City, China, to determine the optimal UAV flight altitude for image acquisition. The findings indicate that at a flight altitude of 60 m, the model reaches the detection accuracy of 77.8% mAP50. These results highlight the model's superior performance in real-world scenarios, demonstrating its robustness and adaptability to complex environments.
目标检测 低照度图像 四头自适应多维特征融合策略 无人机 YOLOv8 object detection low-brightness image four-head adaptive multi-dimensional feature fusion unmanned aerial vehicle YOLOv8 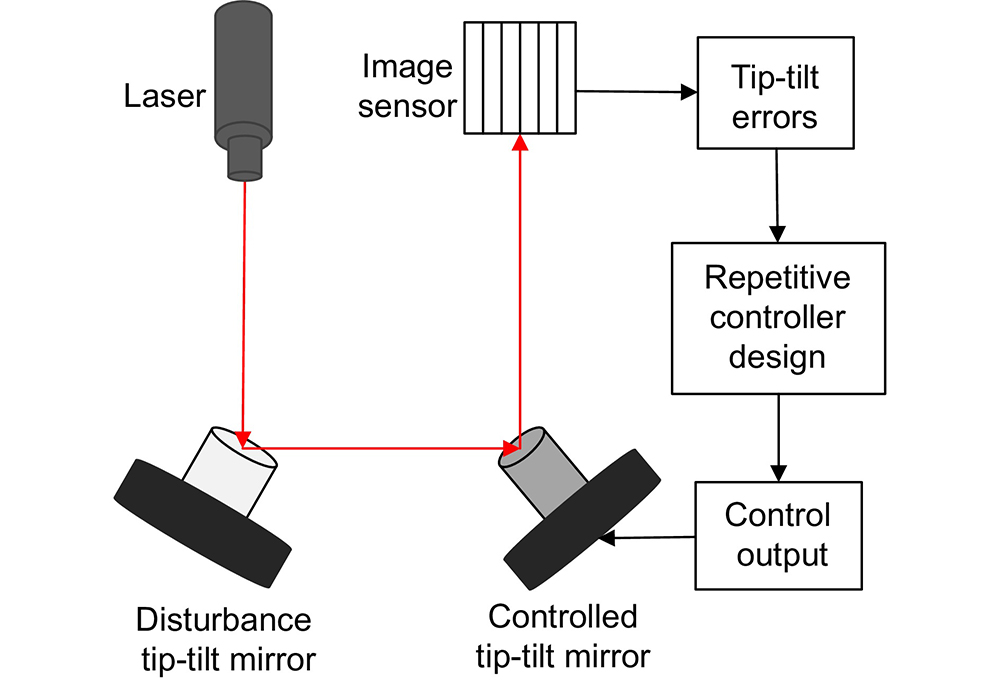
冯念 1,2,3,4唐涛 1,2,3,*胡龙 1,2,3,4
1 中国科学院光场调控科学技术全国重点实验室,四川 成都 610209
2 中国科学院光束控制重点实验室,四川 成都 610209
3 中国科学院光电技术研究所,四川 成都 610209
4 中国科学院大学电子电气与通信工程学院,北京 100049
Overview: In optical telescope systems, the control accuracy with tip-tilt correction systems as a fine tracking link is improved to the level of micro radian or even sub-micro radian. Disturbance suppression, especially high-frequency disturbance suppression outside the closed-loop bandwidth, is the key to achieving high precision stability control of tip-tilt correction systems, so as to approach the diffraction limit of the telescope system. Repetitive control has good performance of periodic trajectory tracking and disturbance suppression and is widely applied to improve the control performance of high-precision control systems, such as nanopositioning stages, power inventers, and hard disk drive systems. Therefore, repetitive control is a promising algorithm for high-frequency disturbance suppression. Firstly, this paper analyzes the problem of high-frequency disturbance suppression of tip-tilt correction systems and summarizes the performance of high-frequency interference suppression based on repetitive control. To solve the problem of natural frequency drift and waterbed amplification of traditional repetitive controllers, a comb-like repetitive controller based on Youla parameterization is designed to suppress high-frequency interference outside the closed-loop bandwidth. In the optimal design of the controller, time delays are compensated by the delay characteristic of the repetitive controller to improve the stability of the closed-loop system in suppressing high-frequency disturbance. In addition, in order to solve the problem that the integer-order repetitive controller is only effective for certain frequency points, especially in most high frequency regions, the controller fails due to interference fluctuations and uncertainties, an all-pass fractional delay filter is optimized, which can suppress high-frequency disturbance at any frequency point up to the Nyquist frequency in the tip-tilt correction system. An additional delay compensation factor is designed to preserve the notch characteristic of the repetitive controller in high-frequency domains and improve the system's stability. Finally, a parallel repetitive control scheme is designed for the non-periodic structure vibration which is difficult to suppress, and its robust stability and effectiveness are discussed. A series of experiments were designed to suppress a single peak disturbance, and the results show that repetitive control suppresses any frequency disturbance up to the Nyquist frequency. Furthermore, the experimental results of multiple periodic and aperiodic disturbance suppression prove that the repetitive controller is superior in dealing with multiple high-frequency disturbances beyond the closed-loop bandwidth. In general, these proposed repetitive controllers have good performance in improving the high-frequency disturbance suppression ability of the tip-tilt correction system, and these algorithms are also suitable for other high-precision control systems in the future.
扰动抑制 倾斜校正 重复控制 高频扰动 disturbance suppression tip-tilt correction repetitive control high-frequency disturbance
The technology successfully resolves the inherent conflict between miniaturization requirements and thermal stability in spaceborne infrared optics. Experimental verification confirms that the focal position preset error remains within one focal depth (±0.07 mm), meeting stringent imaging performance criteria. This approach eliminates complex cryogenic actuators while accommodating material mismatch in compact designs, offering broad applicability for temperature-sensitive optical systems in lightweight satellite platforms. Future work may extend the methodology to multi-spectral systems and optimize parameter weighting algorithms for improved prediction accuracy.
轻小型相机 低温离焦 干涉测量 红外 light and small camera low temperature defocusing interferometric measurement infrared 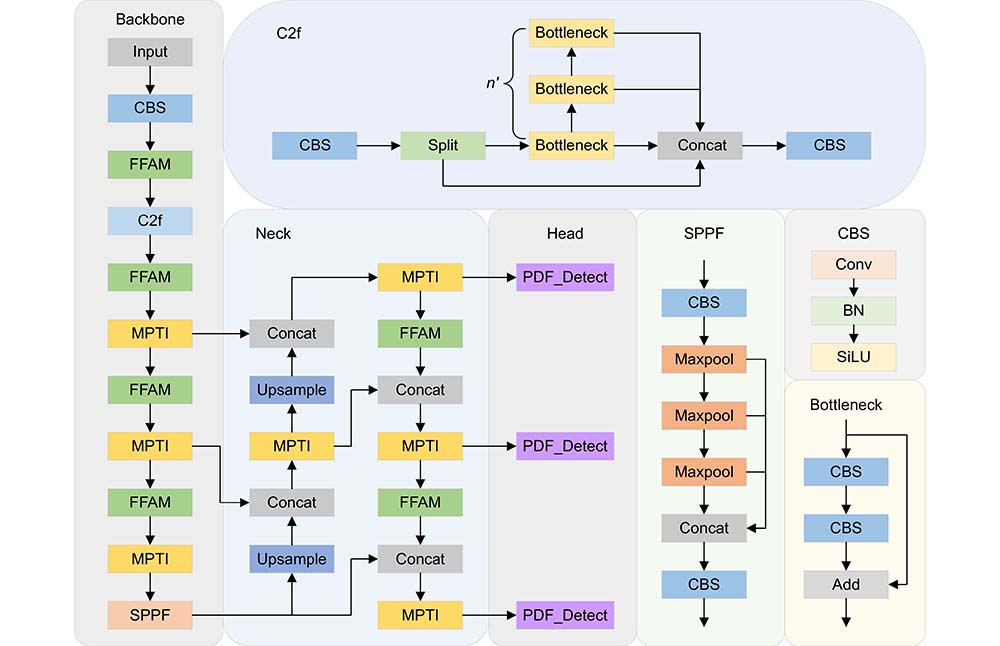
辽宁工程技术大学软件学院,辽宁 葫芦岛 125105
Overview: X-ray image detection of prohibited items plays a crucial role in various fields, including public transportation, logistics, and customs inspection. It is a key technology in image processing and object detection, with the primary task of accurately identifying the category and location of prohibited items within complex background environments to ensure the safety of human life, property, and goods transportation. Unlike natural images, prohibited item images are generated using X-ray imaging technology, where the targets exhibit diverse categories and varying shapes. Moreover, these images are often affected by challenges such as target stacking, occlusion, low contrast, and complex backgrounds, making it difficult to accurately identify the correct targets, thereby leading to missed and false detections. Consequently, achieving precise identification of prohibited items and improving detection efficiency have become critical challenges and focal points in current research. To address the issues of target overlap and occlusion, difficulty in key feature extraction, and missed detection of small-sized contraband in X-ray images, this paper proposes an adaptive panoramic focus X-ray contraband detection algorithm based on the YOLOv8n model. This algorithm incorporates several novel components designed to enhance detection accuracy and efficiency. First, a foreground feature awareness module (FFAM) is proposed to significantly enhance the model's ability to represent the features of foreground targets, enabling accurate identification of contraband objects in overlapping and occluded scenes. Second, a multi-path two-dimensional information integration (MPTI) module is designed to enhance the model's ability to recognize key features by optimizing the interaction and integration of multi-scale features across both channel and spatial dimensions, enabling the extraction of more comprehensive and richer contextual information. Finally, a panoramic dynamic focus detection head (PDF_Detect) is introduced. By incorporating frequency-adaptive dilated convolutions and a dynamic focusing mechanism, the model can adaptively select the optimal receptive field size based on the frequency distribution of features. This enhances the model's ability to focus on small-sized contraband targets, effectively improving the detection of small targets and reducing both missed and false detections in complex scenes. Experiments were conducted on the public datasets SIXray and OPIXray. The experimental results show that the proposed method achieved mAP@0.5 values of 93.3% and 92.5%, representing improvements of 3.6% and 2.8% over the baseline model, respectively, and outperforming other comparative algorithms. These results demonstrate that the proposed algorithm significantly reduces missed and false detections of contraband in X-ray images, exhibiting high accuracy and robustness.
X射线图像 违禁品检测 前景特征感知 多路径双维信息整合 频率自适应空洞卷积 X-ray images contraband detection foreground feature awareness multi-path two-dimensional information integration frequency adaptive dilated convolution 
江西理工大学电气工程与自动化学院,江西 赣州 341000
Overview: Diabetic retinopathy (DR) is a retinal disease caused by microvascular leakage and obstruction resulting from chronic diabetes. Delayed treatment can lead to irreversible vision impairment. However, the number of diabetic patients is increasing year by year, and the retinal fundus lesions are complex and diverse, which makes accurate diagnosis difficult. Even though retinal imaging can reveal structural changes in the retina, screening for ocular lesions remains time-consuming and labor-intensive for experienced clinicians. Therefore, developing an automated DR grading algorithm is of great significance for clinical medical diagnosis. In recent years, deep learning has made significant progress in the field of diabetic retinopathy grading, especially with the widespread application of convolutional neural networks (CNN) in image processing. CNNs can automatically extract multi-level features from images, thus improving the accuracy of retinal disease detection. These advancements not only enhance the grading accuracy of diabetic retinopathy but also provide ophthalmologists with more efficient diagnostic tools, promoting the application of intelligent diagnostic systems in clinical settings. However, there are still some shortcomings in the retinal disease grading task: the class distribution in datasets is imbalanced, and the lesion features in retinal images often present small and complex shapes, making them difficult to identify. Additionally, it is challenging to balance both macro and micro features simultaneously. To address these issues, this paper proposes a retinal disease grading algorithm that integrates PVTv2 and DenseNet121 with dual attention mechanisms. The algorithm first uses a dual-branch network consisting of PVTv2 and DenseNet121 to extract global and local information from retinal images. Then, spatial-channel collaborative attention modules and multi-frequency multi-scale modules are applied at the outputs of PVTv2 and DenseNet121 to optimize local feature details, highlight micro-lesion features, and improve the model's sensitivity to complex micro-lesion characteristics and its ability to locate lesions. Furthermore, a neuron-cross-fusion module is designed to establish long-range dependencies between macroscopic lesion layout and microscopic texture information, thus improving the grading accuracy of retinal diseases. Finally, a hybrid loss function is used to mitigate the imbalance in model attention across different grades caused by uneven sample distribution. The algorithm is experimentally validated on the IDRID and APTOS 2019 datasets. On the IDRID dataset, the secondary weighted coefficient, accuracy, sensitivity, and specificity are 90.68%, 80.58%, 95.65%, and 97.06%, respectively. On the APTOS 2019 dataset, the secondary weighted coefficient, accuracy, sensitivity, and area under the ROC curve are 90.35%, 84.83%, 87.94%, and 93.22%, respectively. The experimental results show that the proposed algorithm has significant application value in retinal disease grading and provides a new approach for intelligent grading and clinical diagnosis assistance for retinal diseases.
视网膜病变分级 空间通道协同注意力模块 多频率多尺度注意力模块 神经元交叉融合模块 retinal disease grading spatial-channel synergistic attention module multi-frequency multi-scale attention module neuron cross fusion module 








